Shards in Elastic Search- When we have a large number of documents, we may come to a point where a single node may not be enough—for example, because of RAM limitations, hard disk capacity, insufficient processing power, and inability to respond to client requests fast enough. In such a case, data can be divided into smaller parts called shards (where each shard is a separate Apache Lucene index). Each shard can be placed on a different server, and thus, your data can be spread among the cluster nodes. When you query an index that is built from multiple shards, Elasticsearch sends the query to each relevant shard and merges the result in such a way that your application doesn’t know about the shards. In addition to this, having multiple shards can speed up the indexing.
clustering allows us to store information volumes that exceed abilities of a single server. To achieve this requirement, ElasticSearch spread data to several physical Lucene indices. Those Lucene indices are called shards and the process of this spreading is called sharding. ElasticSearch can do this automatically and all parts of the index (shards) are visible to the user as one-big index. Note that besides this automation, it is crucial to tune this mechanism for particular use case because the number of shard index is built or is configured during index creation and cannot be changed later, at least currently.
So if you have an index with 100 documents and a cluster with 2 nodes, each node will hold 50 documents if the shard_number is 2. (Ignoring replicas of course)
That’s a little of the “infinite scaling magic ” because each machine in your cluster only have to deal with some pieces of your data.
Replica
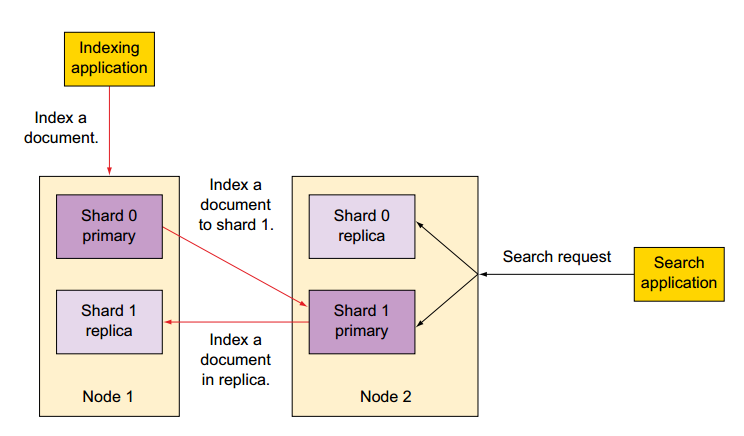
In order to increase query throughput or achieve high availability, shard replicas can be used. A replica is just an exact copy of the shard, and each shard can have zero or more replicas. In other words, Elasticsearch can have many identical shards and one of them is automatically chosen as a place where the operations that change the index are directed. This special shard is called a primary shard, and the others are called replica shards. When the primary shard is lost (for example, a server holding the shard data is unavailable), the cluster will promote the replica to be the new primary shard.
Sharing allows us to push more data into ElasticSearch that is possible for a single node to handle. Replicas can help where load increases and a single node is not able to handle all the requests. The idea is simple: create additional copy of a shard, which can be used for queries just as original, primary shard. Note that we get safety for free. If the server with the shard is gone, ElasticSearch can use replica and no data is lost. Replicas can be added and removed at any time, so you can adjust their numbers when needed..
Replicas can be added or removed at runtime—primaries can’t You can change the number of replicas per shard at any time because replicas can always be created or removed. This doesn’t apply to the number of primary shards an index is divided into; you have to decide on the number of shards before creating the index. Keep in mind that too few shards limit how much you can scale, but too many shards impact performance. The default setting of five is typically a good start
A node is an instance of Elasticsearch. When you start Elasticsearch on your server, you have a node. If you start Elasticsearch on another server, it’s another node. You can even have more nodes on the same server by starting multiple Elasticsearch processes. Multiple nodes can join the same cluster. As we’ll discuss later in this chapter, starting nodes with the same cluster name and otherwise default settings is enough to make a cluster. With a cluster of multiple nodes, the same data can be spread across multiple servers. This helps performance because Elasticsearch has more resources to work with. It also helps reliability: if you have at least one replica per shard, any node can disappear and Elasticsearch will still serve you all the data. For an application that’s using Elasticsearch, having one or more nodes in a cluster is transparent. By default, you can connect to any node from the cluster and work with the whole data just as if you had a single node. Although clustering is good for performance and availability, it has its disadvantages: you have to make sure nodes can communicate with each other quickly enough and that you won’t have a split brain (two parts of the cluster that can’t communicate and think the other part dropped out). To address such issues,
WHAT HAPPENS WHEN YOU SEARCH AN INDEX?
When you search an index, Elasticsearch has to look in a complete set of shards for that index Those shards can be either primary or replicas because primary and replica shards typically contain the same documents. Elasticsearch distributes the search load between the primary and replica shards of the index you’re searching, making replicas useful for both search performance and fault tolerance. Next we’ll look at the details of what primary and replica shards are and how they’re allocated in an Elasticsearch cluster.
Happy Sharding in elastic Search with Vinay….. 🙂