Oracle launch Oracle Container Cloud Service finally last year. Oracle Container Cloud Service – based on the technology and developed by the team that came from the StackEngine acquisition by Oracle – is a cloud-native and Docker compatible container as a service (CaaS) solution integrated into the Oracle Cloud. It is enterprise ready and with comprehensive tooling to compose, deploy, orchestrate, schedule, and operate Docker container-based applications on the Oracle Cloud. Designed for Dev, Dev/Test, DevOps, and Container Native use cases, OCCS enables self-healing scheduling, built-in service discovery, and CI/CD integrations via webhooks and REST API..It also comes in competition with the following competitor in world
– Docker for AWS or Azure
– Amazon Elastic Container Service
– Google Container Engine
– Azure Container Service
– DC/OS by Mesosphere
– OpenShift by Red Hat
Oracle Container Cloud Service offers Development and Operations teams the benefits of easy and secure Docker containerization when building and deploying applications.OCCS is the newest addition in the Oracle Cloud landscape. It’s a PaaS service that addresses those additional requirements for running Docker in production.
Manager and Worker Services
To get started with the Oracle Container Cloud Service you first define an OCCS service that represents a set of hosts used for OCCS. A service always consists of a manager node and one or more worker nodes.
The manager node orchestrates the deployment of containers to the worker nodes. The worker nodes host the containers or stacks of containers. The set of worker nodes for a service can later be further subdivided into pools that build a resource group.
Every configured OCCS service has its own admin user and password. To set up an OCCS service, you define its service name and either create a new SSH key or specify an existing one. Using this SSH key you can connect to the service from the command-line.
Oracle Container Cloud Service:
– provides an easy-to-use interface to manage the Docker environment
– provides out-of-the-box examples of containerized services and application stacks that can be deployed in one click
– enables developers to easily connect to their private Docker registries (so they can ‘bring their own containers’)
– enables developers to focus on building containerized application images and Continuous Integration/Continuous Delivery (CI/CD) pipelines, not on learning complex orchestration technologies
You can request trial account for 30 days for from Oracle.com. For learn how to use trail account please see below video.
Container cloud service uses docker.Let learn about Docker,
Docker
Docker has been a tremendous success over the last three years. From an almost unknown and rather technical open source technology in 2014, it has evolved into a standardized runtime environment now officially supported for many Oracle enterprise products.
Basics
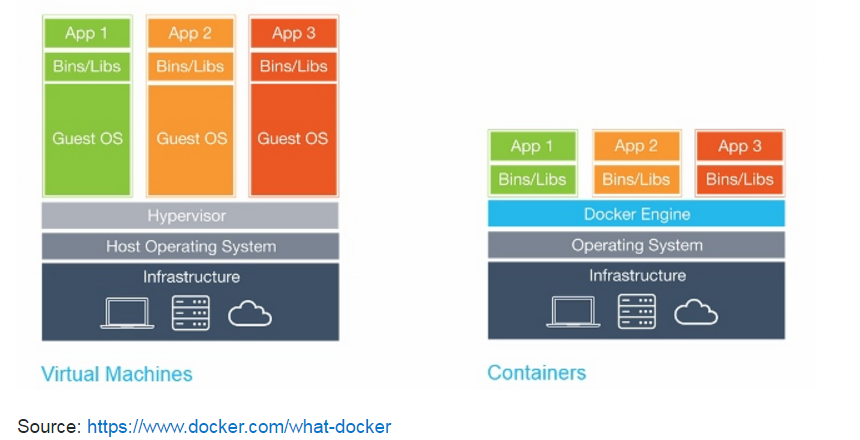
The core concepts of Docker are images and containers. A Docker image contains everything that is needed to run your software: the code, a runtime (e.g. the JVM), drivers, tools, scripts, libraries, deployments, etc.
A Docker container is a running instance of a Docker image. However, unlike in traditional virtualization with a type 1 or type 2 hypervisor, a Docker container runs on the kernel of the host operating system. Within a Docker image there is no separate operating system,
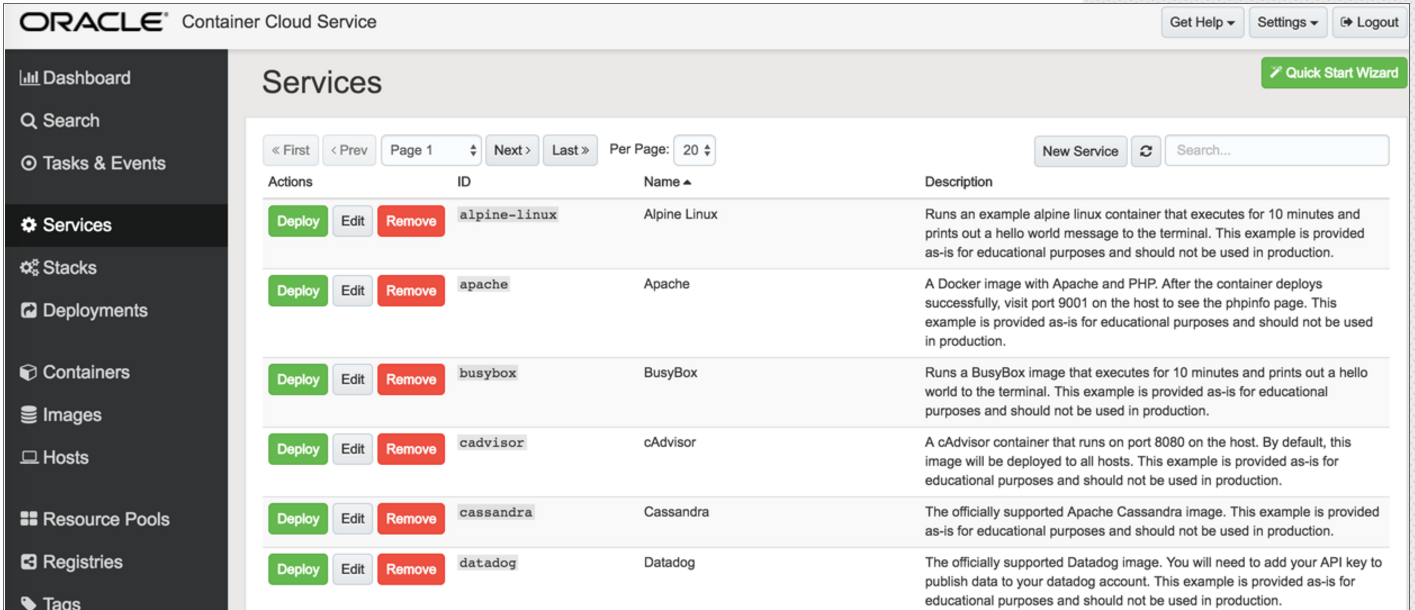
Oracle Container Service is built upon Oracle’s StackEngine acquisition .You can run docker on container services.OCCS comes with several predefined OCCS container services. An OCCS container service defines a Docker service together with the necessary configuration settings for running a Docker image and its deployment directives.Oracle Container Cloud Service (OCCS) comes with some popular service examples like apache, nginx, jenkins, logstash, mariadb etc.
 on a host, plus default deployment directives. Service is neither container nor image running in containers. It is a high-level configuration objects that you can create, deploy, and manage using Oracle Container Cloud Service. Think of a service as a container ‘template’, or as a set of instructions to follow to deploy a running container.
on a host, plus default deployment directives. Service is neither container nor image running in containers. It is a high-level configuration objects that you can create, deploy, and manage using Oracle Container Cloud Service. Think of a service as a container ‘template’, or as a set of instructions to follow to deploy a running container.
Stack – Stack is all the necessary configuration for running a set of services as Docker containers in a coordinated way and managed as a single entity, plus default deployment directives. Think of it as multi-container application. Stacks themselves are neither containers nor images running in containers, but rather are high-level configuration objects that you can create, deploy, and manage using Oracle Container Cloud Service. For example, a stack might be one or more WildFly containers and a Couchbase container. Likewise, a cluster of database or application nodes can be built as a stack.
Deployment – A Deployment comprises a service or stack in which Docker containers are managed, deployed, and scaled according to a set of orchestration rules that you’ve defined. A single deployment can result in the creation of one or many Docker containers, across one or many hosts in a resource pool.
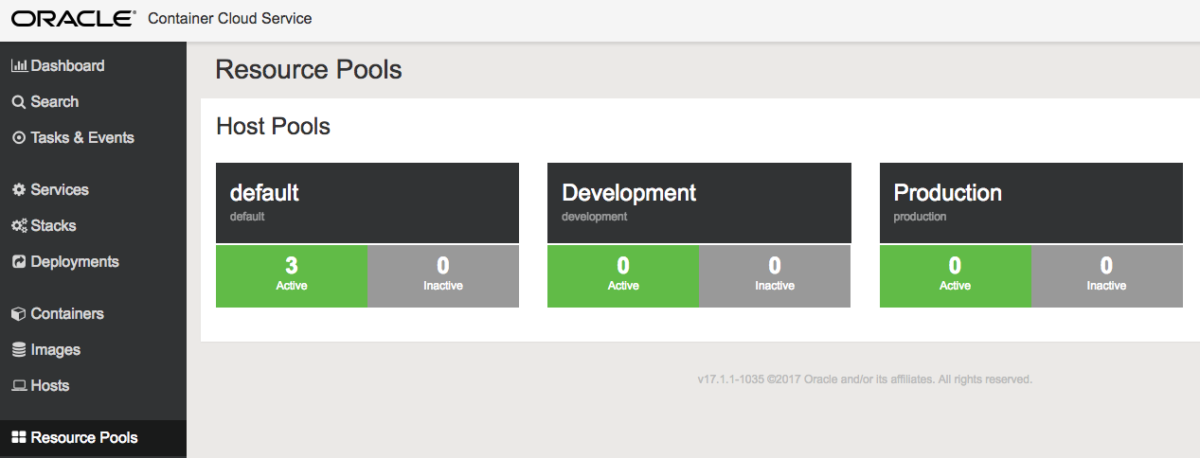
Resource Pool – Resource pools are a way to organize hosts and combine them into isolated groups of compute resources. Resource pools enable you to manage your Docker environment more effectively by deploying services and stacks efficiently across multiple hosts.Three resource pools are defined out of the box.
Stacks
OCCS does not only define and deploy single services. You can also link services together and start them as a stack. The OCCS console already comes with several predefined stack examples, such as WordPress with a database or a Redis cluster with master and slave.
Stacks are defined by a YAML file that lists the contained services. You can define environment variables for every service in a stack.
Please give a trying OCCS.Happy Oracle Cloud learning.