Kafka is distributed publish-subscribe messaging system. It provides solutions to handle all activities stream data. It also supports Hadoop platform. It have mechanism for parallel load into Hadoop.
Apache Kafka is an open source, distributed messaging system that enables you to build real-time applications using Streaming data.
Apache Kafka Overview
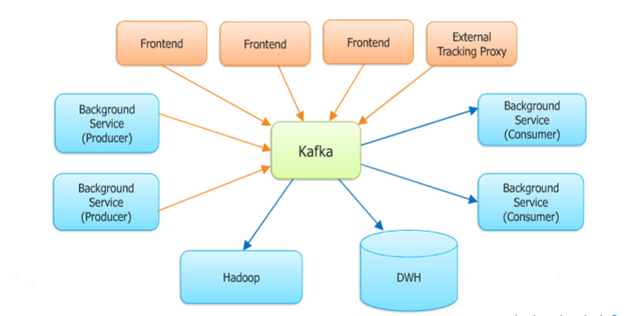
Kafka maintains feeds of messages in categories called topics. Can be call these process as publish messages to a Kafka topic producers. We’ll call processes that subscribe to topics and process the feed of published messages consumers. Kafka is run as a cluster comprised of one or more servers each of which is called a broker. We can also run Kafka deployment on Amazon EC2 that provides a high performance, scalable solution for ingesting streaming data. To deploy Kafka on Amazon EC2, you need to select and provision your EC2 instance types, install and configure the software components including Kafka and Apache Zookeeper, and then provision the block storage required to accommodate your streaming data throughput using Amazon Elastic Block Store (EBS).
Key Concepts –
-
Topic is divided in partitions.
-
The message order is only guarantee inside a partition
-
Consumer offsets are persisted by Kafka with a commit/auto-commit mechanism.
-
Consumers subscribes to topics
-
Consumers with different group-id receives all messages of the topics they subscribe. They consume the messages at their own speed.
-
Consumers sharing the same group-id will be assigned to one (or several) partition of the topics they subscribe. They only receive messages from their partitions. So a constraint appears here: the number of partitions in a topic gives the maximum number of parallel consumers.
-
The assignment of partitions to consumer can be automatic and performed by Kafka (through Zookeeper). If a consumer stops polling or is too slow, a process call “re-balancing” is performed and the partitions are re-assigned to other consumers.
Kafka normally divides topic in multiply partitions. Each partition is an ordered, immutable sequence of messages that is continually appended to.
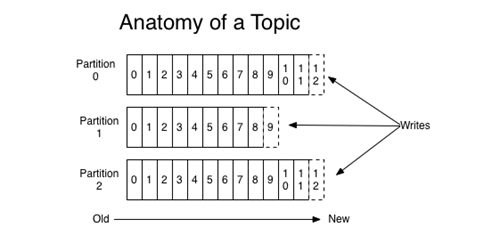
Source: http://kafka.apache.org/documentation.html
-
A message in a partition is identified by a sequence number called offset.
-
The FIFO is only guarantee inside a partition.
-
When a topic is created, the number of partitions should be given, for instance:
-
The producer can choose which partition will get the message or let Kafka decides for him based on a hash of the message key (recommended). So the message key is important and will be the used to ensure the message order.
-
Moreover, as the consumer will be assigned to one or several partition, the key will also “group” messages to a same consumer.
Advantages-
-
With Kafka we can easily handle hundreds of thousands of messages in a second, which makes Kafka high throughput messaging system.
-
Kafka’s cluster can be expanded with no downtime, making Kafka highly scalable.
-
Messages are replicated, which provided reliability and durability.
-
It is fault tolerant.
-
Kafka also supports micro-batching.
Kafka components
-
Producer is process that can publish a message to a topic.
-
Consumer is a process that can subscribe to one or more topics and consume messages published to topics.
-
Topic category is the name of the feed to which messages are published.
-
Broker is a process running on single machine
-
Cluster is a group of brokers working together.
-
Broker management done by Zookeeper.
Kafka Cluster Management- Zookeeper 
Entire cluster management of Kafka done by Zookeeper. Hey wait, why the name as Zookeeper? Because Hadoop is like elephant, then hive and pig is there. So it’s Zookeeper who manages all these. J (Manager of all animal as zookeeper). It is open source Apache project. It provides a centralized infrastructure and services that enable synchronization across cluster. Its common object used across large cluster environments maintained by in Zookeeper. It is not limited to Kafka. Strom and Spark also used this. Its services are used by large scale application to coordinate distributed processing across large cluster.
It selects leader node in Kafka and resource management. It also maintains node (Broker) down and up i.e. is configuration management. It also keep state of last message processed. ZooKeeper is used for managing and coordinating Kafka broker. ZooKeeper service is mainly used to notify producer and consumer about the presence of any new broker in the Kafka system or failure of the broker in the Kafka system. As per the notification received by the Zookeeper regarding presence or failure of the broker then producer and consumer takes decision and starts coordinating their task with some other broker.
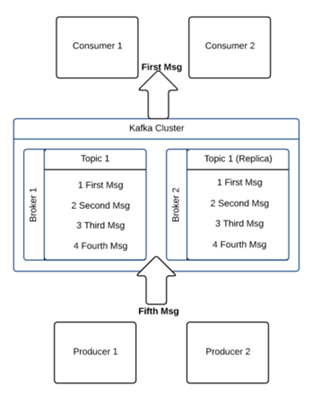
Cluster Management by Zookeeper
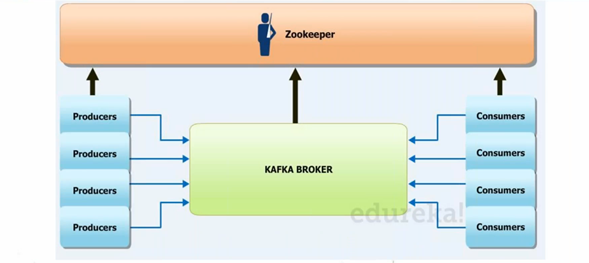
Above picture say it all. Producers connect to kafka broker and consumer as well connect to broker. New broker can be added, which make it more scalable. Zookeeper do configuration Management with broker.
Apache kafka also fit with Oracle Product. Oracle SOA, Oracle API management and other Fusion middleware products. Soon , will publish article with how we can connect with Kafka with Oracle FMW.Stay tuned.
Happy Distrubited messaging with Vinay in Kafka. J