ElasticSearch is an Open Source (Apache 2), Distributed Search Engine built on top of Apache Lucene.
Elasticsearch is a NOSQL, distributed full text database. Which means that this database is document based instead of using tables or schema, we use documents. Elasticsearch is much more than just Lucene and much more than “just” full text search. It is also:A distributed real-time document store where every field is indexed and searchable. A distributed search engine with real-time analytics. Capable of scaling to hundreds of servers and petabytes(Figure -1) of structured and unstructured data .
History – The project was started in 2010 by Shay Banon. Shay wanted to create a storage and search engine that would be easy to operate. Elasticsearch is based on the Lucene engine on top of which Shay added an http rest interface which resulted in a distributed search engine that is incredibly easy to scale and returns results at lightning speed
Need of Elasticsearch – As a developer or business guy who is used to traditional relational databases, we often face challenges to find information in millions of record in rdbms table. Suppose developer had to search in millions of record in table with 100’s of column. Think about the search time. I am sure, who tried, and they frustrated to build a fast system. Situation gets worst, when it needed to search tables that had millions of records, resulting in overly complex database views/stored-procedures and adding full text search on relational database fields. Something which I personally dislike, as it made the database twice the size and the speed was not optimal either. Relational databases are simply not built for such operations.
In normal RDBMS table, we try searching like searchParam
Select * from tableName WHERE columnName LIKE ‘%searchParam %’;
I am sure, by like this, you can’t search everything and it’s not performance optimal.
Now with Elasticsearch we can achieve the speed we would like, as it lets us index millions of documents. Now definitely, we need a system of something, in which we can make search faster.
Real usecase-
Elasticsearch can be used for various usage, for example it can be used as a blog storage engine in case you would like your blog to be searchable. Traditional SQL doesn’t readily give you the means to do that.
How about Analytics tools? Most software generates tons of data that is worth analyzing, Elasticsearch comes with Logstash and Kibanato give you a full analytics system.
Finally, I like to see Elasticsearch as Data ware house, where you have documents with many different attributes and non-predictable schemas. Since Elasticsearch is schemaless, it won’t matter that you store various documents there, you will still be able to search them easily and quickly.On the other hand having a powerful tool like Kibana would allow you to have a custom dashboard that gives the opportunity for non-technical managers to view and analyze this data.
For me real use case to build search engine with over 5 erp for my organization. A search engine, where we can search almost everything within company different ERP system. In my organization,we have 5 different ERP system, which caters different use case for different business unit. So there are 5 data source, in which I need to make search. User will have one search field, on which they can search anything without mentioning what they want to search it.Portal should display all result based on search param to user. Sounds interesting? J Believe me it’s more challenging than, it sounds interesting 😛
ElasticSearch can be good fit here. We can get all information from 5 different ERP and do data indexing and after that search will be very faster and awesome , same as google.
How Elasticsearch saves data?
Elasticsearch does not have tables, and a schema is not required. Elasticsearch stores data documents that consist of JSON strings inside an index.
The field is like the columns of the SQL database and the value represents the data in the row cells.
When you save a document in Elasticsearch, you save it in an index. An
ElasticSearch is a great open source search engine built on top of Apache Lucene. Its features and upgrades allow it to basically function just like a schema-less JSON datastore that can be accessed using both search queries and regular database CRUD commands.
Here are the main “disadvantages” I see:
- Transactions – There is no support for transactions or processing on data manipulation.
- Data Availability – ES makes data available in “near real-time” which may require additional considerations in your application (ie: comments page where a user adds new comment, refreshing the page might not actually show the new post because the index is still updating).
- Durability – ES is distributed and fairly stable but backups and durability are not as high priority as in other data stores. ElasticSearch has come a long way in the past few years since this original answer and now has better features, backup methods and even realtime indexing. Please review the official site for more information.
If you can deal with these issues then there’s certainly no reason why you can’t use ElasticSearch as your primary data store. It can actually lower complexity and improve performance by not having to duplicate your data but again this depends on your specific use case.
index is like a database in relational database. An index is saved across multiple shards and shards are then stored in one or more servers which are called nodes, multiple nodes form a cluster.
You can download the latest version of Elasticsearch from elasticsearch.org/download.
curl -L -O http://download.elasticsearch.org/PATH/TO/VERSION.zip
unzip elasticsearch-$VERSION.zip
cd elasticsearch-$VERSION
Elasticsearch is now ready to run. You can start it up in the foreground with:
./bin/elasticsearch
Add -d if you want to run it in the background as a daemon.
Test it out by opening another terminal window and running:
curl ‘http://localhost:9200/?pretty’
You should see a response like this:
{
“status”: 200,
“name”: “Shrunken Bones”,
“version”: {
“number”: “1.4.0”,
“lucene_version”: “4.10”
},
“tagline”: “You Know, for Search”
}
This means that your Elasticsearch cluster is up and running, and we can start experimenting with it.
Clusters and nodes
A node is a running instance of Elasticsearch. A cluster is a group of nodes with the same cluster.name that are working together to share data and to provide failover and scale, although a single node can form a cluster all by itself.
You should change the default cluster.name to something appropriate to you, like your own name, to stop your nodes from trying to join another cluster on the same network with the same name!
You can do this by editing the elasticsearch.yml file in the config/ directory, then restarting Elasticsearch. When Elasticsearch is running in the foreground, you can stop it by pressing Ctrl-C, otherwise you can shut it down with the api
curl –XPOST ‘http://localhost:9200/_shutdown’
Some of common terminologies in elastic search-
A cluster is a collection of one or more nodes (servers) that together holds your entire data and provides federated indexing and search capabilities across all nodes. A cluster is identified by a unique name which by default is “elasticsearch”. This name is important because a node can only be part of a cluster if the node is set up to join the cluster by its name.
Node
A node is a single server that is part of your cluster, stores your data, and participates in the cluster’s indexing and search capabilities. Just like a cluster, a node is identified by a name which by default is a random Marvel character name that is assigned to the node at startup. You can define any node name you want if you do not want the default. This name is important for administration purposes where you want to identify which servers in your network correspond to which nodes in your Elasticsearch cluster.
Index
An index is a collection of documents that have somewhat similar characteristics. For example, you can have an index for customer data, another index for a product catalog, and yet another index for order data. You will provide different index name for different data. An index is identified by a name and this name is used to refer to the index when performing indexing, search, update, and delete operations against the documents in it.
Shards & Replicas
An index can potentially store a large amount of data that can exceed the hardware limits of a single node. For example, a single index of a billion documents taking up 1TB of disk space may not fit on the disk of a single node or may be too slow to serve search requests from a single node alone.
To solve this problem, Elasticsearch provides the ability to subdivide your index into multiple pieces called shards. When you create an index, you can simply define the number of shards that you want. Each shard is in itself a fully-functional and independent “index” that can be hosted on any node in the cluster.
Now talking about how elastic search can help in Oracle ADF/WebCenter or fusion middleware technologies.
I will be publishing series of tutorial for elasticSearch. Will try to show, how we can use with ADF/Webcenter portal as well.Following architecture can be used in ADF/WebCenter Portal Application.
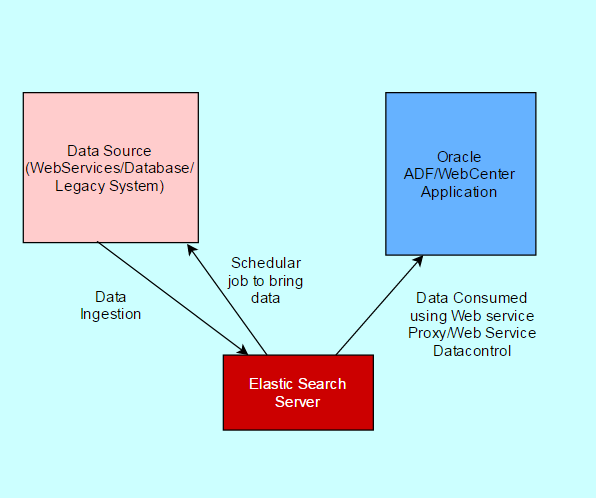
Elastic Search is very fast in comparison to ADF Search. In ADF, you can search using query panel or custom search box. With this you can combine all data on backend and search with one inputText to all tables schema or all backend data. Search response time is in ms. In WebCenter Portal Oracle Secure Enterprise Search is also going to replace with Elastic Search. So its good time to get into this.
Elastic Search can also be used in WebCenter content to searching documents. See one of great demo by Team Informatics in this youtube channel.
We can also use Apache Kafka with elastic search for real time data ingestion and searching. I will cover in coming post.
Till then, Happy searching by elasticSearch with Vinay in techartifact. Data source can be webservices, data base or live streaming data. In this, we have schedular to bring data or ingest data in elastic search server. ADF/WebCenter Portal application can consume data using querying into Elastic Search Server.
Ref – https://www.elastic.co/guide/en/elasticsearch/reference/2.2/_basic_concepts.html http://joelabrahamsson.com/elasticsearch-101/